Qemu fsfreeze hook
Tratto da https://kb.kurgan.org/PVE
Uso di Qemu-agent
Abilitando l’agent nella configurazione della VM, e installando l’agent dentro la VM, è possibile gestire alcune funzioni di comunicazione fra host e guest. Una delle funzioni più comode è quella del freeze del file system nel momento in cui viene fatto uno snapshot (per esempio per i backup) per avere dei backup il più possibile congruenti. Per il file system, il semplice fatto di avere l’agente installato e abilitato è sufficiente. Per un database, tuttavia, è opportuno configurare uno script apposta.
Il pacchetto Debian da installare nel guest si chiama qemu-guest-agent
Qemu-agent e Mysql su guest Debian
Per fare interagire Mysql (o Mariadb) con qemu-agent occorre:
- Installare il pacchetto dell’agent
-
Modificare il file di init /etc/init.d/qemu-guest-agent aggiungendo il parametro “-F” nella variabile DAEMON_ARGS, in queso modo: DAEMON_ARGS="-F"
- Riavviare qemu-guest-agent
-
Creare la directory /etc/qemu
-
Creare la directory /etc/qemu/fsfreeze-hook.d
-
Creare lo script /etc/qemu/fsfreeze-hook, contenente quanto segue:
#!/bin/bash # This script is executed when a guest agent receives fsfreeze-freeze and # fsfreeze-thaw command, if it is specified in --fsfreeze-hook (-F) # option of qemu-ga or placed in default path (/etc/qemu/fsfreeze-hook). # When the agent receives fsfreeze-freeze request, this script is issued with # "freeze" argument before the filesystem is frozen. And for fsfreeze-thaw # request, it is issued with "thaw" argument after filesystem is thawed. LOGFILE=/var/log/qga-fsfreeze-hook.log FSFREEZE_D=$(dirname -- "$0")/fsfreeze-hook.d # Check whether file $1 is a backup or rpm-generated file and should be ignored is_ignored_file() { case "$1" in *~ | *.bak | *.orig | *.rpmnew | *.rpmorig | *.rpmsave | *.sample) return 0 ;; esac return 1 } # Iterate executables in directory "fsfreeze-hook.d" with the specified args [ ! -d "$FSFREEZE_D" ] && exit 0 for file in "$FSFREEZE_D"/* ; do is_ignored_file "$file" && continue [ -x "$file" ] || continue printf "$(date): execute $file $@\n" >>$LOGFILE "$file" "$@" >>$LOGFILE 2>&1 STATUS=$? printf "$(date): $file finished with status=$STATUS\n" >>$LOGFILE done exit 0 -
Creare lo script /etc/qemu/fsfreeze-hook.d/mysql-flush.sh contenente quanto segue (nota se occorre o meno inserire il parametro per la password nella variabile MYSQL_OPTS):
#!/bin/bash # Flush MySQL tables to the disk before the filesystem is frozen. # At the same time, this keeps a read lock in order to avoid write accesses # from the other clients until the filesystem is thawed. MYSQL="/usr/bin/mysql" MYSQL_OPTS="-uroot" #"-prootpassword" FIFO=/var/run/mysql-flush.fifo # Check mysql is installed and the server running [ -x "$MYSQL" ] && "$MYSQL" $MYSQL_OPTS < /dev/null || exit 0 flush_and_wait() { printf "FLUSH TABLES WITH READ LOCK \\G\n" trap 'printf "$(date): $0 is killed\n">&2' HUP INT QUIT ALRM TERM read < $FIFO printf "UNLOCK TABLES \\G\n" rm -f $FIFO } case "$1" in freeze) mkfifo $FIFO || exit 1 flush_and_wait | "$MYSQL" $MYSQL_OPTS & # wait until every block is flushed while [ "$(echo 'SHOW STATUS LIKE "Key_blocks_not_flushed"' |\ "$MYSQL" $MYSQL_OPTS | tail -1 | cut -f 2)" -gt 0 ]; do sleep 1 done # for InnoDB, wait until every log is flushed INNODB_STATUS=$(mktemp /tmp/mysql-flush.XXXXXX) [ $? -ne 0 ] && exit 2 trap "rm -f $INNODB_STATUS; exit 1" HUP INT QUIT ALRM TERM while :; do printf "SHOW ENGINE INNODB STATUS \\G" |\ "$MYSQL" $MYSQL_OPTS > $INNODB_STATUS LOG_CURRENT=$(grep 'Log sequence number' $INNODB_STATUS |\ tr -s ' ' | cut -d' ' -f4) LOG_FLUSHED=$(grep 'Log flushed up to' $INNODB_STATUS |\ tr -s ' ' | cut -d' ' -f5) [ "$LOG_CURRENT" = "$LOG_FLUSHED" ] && break sleep 1 done rm -f $INNODB_STATUS ;; thaw) [ ! -p $FIFO ] && exit 1 echo > $FIFO ;; *) exit 1 ;; esac - Rendere eseguibili da root i due script appena creati
Fatto questo, quando si lancia un backup il DB verrà flushato e lockato in scrittura per un secondo circa, il tempo di creare lo snapshot per il backup, poi verrà immediatamente sbloccato. Il risultato, nel log del guest, è una cosa tipo:
Jul 21 14:24:23 web1 qemu-ga: info: guest-fsfreeze called Jul 21 14:24:23 web1 qemu-ga: info: executing fsfreeze hook with arg 'freeze' Jul 21 14:24:23 web1 qemu-ga: info: executing fsfreeze hook with arg 'thaw'
andrea
- Published in Sistemistica, Tips & Tricks, Virtualizzazione
Centos 7 Cluster PCS
Installo due VM in VirtualBox identiche (4C, 4Gb RAM, 32Gb HDD) con una versione minimale di Centos 7 aggiornata.
Aggiorno il kernel a 4.16 dal repository elrepo.
# rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org # rpm -Uvh http://www.elrepo.org/elrepo-release-7.0-3.el7.elrepo.noarch.rpm # yum --disablerepo="*" --enablerepo="elrepo-kernel" list available # yum --enablerepo=elrepo-kernel install kernel-ml kernel-ml-devel
Edito il file /etc/default/grub
GRUB_TIMEOUT=5 GRUB_DEFAULT=0 GRUB_DISABLE_SUBMENU=true GRUB_TERMINAL_OUTPUT="console" GRUB_CMDLINE_LINUX="rd.lvm.lv=centos/root rd.lvm.lv=centos/swap crashkernel=auto rhgb quiet" GRUB_DISABLE_RECOVERY="true"
Ed eseguo per attivare la modifica precedente.
# grub2-mkconfig -o /boot/grub2/grub.cfg
Aggiungo qualche pacchetto.
# yum install epel-release.noarch # yum update # yum group install "Development Tools" # yum install bzip2 net-tools psmisc nmap acpid unzip
Modifico /etc/hosts sui due nodi.
192.168.254.83 nodeA.netlite.it nodeA 192.168.254.84 nodeB.netlite.it nodeB
Installo i numerosi pacchetti necessari al cluster.
# yum install pcs fence-agents-all -y
Aggiungo le regole di firewalling.
# firewall-cmd --permanent --add-service=high-availability # firewall-cmd --add-service=high-availability # firewall-cmd --list-service dhcpv6-client ssh high-availability
Modifico la password dell’utente hacluster.
# passwd hacluster Changing password for user hacluster. New password: BAD PASSWORD: The password is shorter than 8 characters Retype new password: passwd: all authentication tokens updated successfully.
Avvio i servizi.
# systemctl start pcsd.service # systemctl enable pcsd.service
Autorizzo i nodi del cluster.
# pcs cluster auth nodeA.netlite.it nodeB.netlite.it Username: hacluster Password: nodeA.netlite.it: Authorized nodeB.netlite.it: Authorized
Inizializzo il cluster.
# pcs cluster setup --start --name ClusterTest nodeA.netlite.it nodeB.netlite.it Destroying cluster on nodes: nodeA.netlite.it, nodeB.netlite.it... nodeA.netlite.it: Stopping Cluster (pacemaker)... nodeB.netlite.it: Stopping Cluster (pacemaker)... nodeB.netlite.it: Successfully destroyed cluster nodeA.netlite.it: Successfully destroyed cluster Sending 'pacemaker_remote authkey' to 'nodeA.netlite.it', 'nodeB.netlite.it' nodeA.netlite.it: successful distribution of the file 'pacemaker_remote authkey' nodeB.netlite.it: successful distribution of the file 'pacemaker_remote authkey' Sending cluster config files to the nodes... nodeA.netlite.it: Succeeded nodeB.netlite.it: Succeeded Starting cluster on nodes: nodeA.netlite.it, nodeB.netlite.it... nodeB.netlite.it: Starting Cluster... nodeA.netlite.it: Starting Cluster... Synchronizing pcsd certificates on nodes nodeA.netlite.it, nodeB.netlite.it... nodeA.netlite.it: Success nodeB.netlite.it: Success Restarting pcsd on the nodes in order to reload the certificates... nodeA.netlite.it: Success nodeB.netlite.it: Success
Abilito il cluster.
# pcs cluster enable --all
Visualizzo lo stato.
# pcs cluster status Cluster Status: Stack: corosync Current DC: nodeA.netlite.it (version 1.1.16-12.el7_4.8-94ff4df) - partition with quorum Last updated: Tue Apr 3 13:02:21 2018 Last change: Tue Apr 3 13:00:43 2018 by hacluster via crmd on nodeA.netlite.it 2 nodes configured 0 resources configured PCSD Status: nodeA.netlite.it: Online nodeB.netlite.it: Online
Status dettagliati.
# pcs status Cluster name: ClusterTest WARNING: no stonith devices and stonith-enabled is not false Stack: corosync Current DC: nodeA.netlite.it (version 1.1.16-12.el7_4.8-94ff4df) - partition with quorum Last updated: Tue Apr 3 13:02:53 2018 Last change: Tue Apr 3 13:00:43 2018 by hacluster via crmd on nodeA.netlite.it 2 nodes configured 0 resources configured Online: [ nodeA.netlite.it nodeB.netlite.it ] No resources Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled
Disabilito i device stonith (meglio non farlo ma per test è ok).
# pcs property set stonith-enabled=falseIn caso sia necessario attivare i devices qui c’è un buon punto di partenza STONITH.
Configuro un FS.
# pcs resource create httpd_fs Filesystem device="/dev/mapper/vg_apache-lv_apache" directory="/var/www" fstype="ext4" --group apache
Configuro un VIP.
# pcs resource create httpd_vip IPaddr2 ip=192.168.12.100 cidr_netmask=24 --group apache
Configuro un servizio.
# firewall-cmd --add-service=http # firewall-cmd --permanent --add-service=http # pcs resource create httpd_ser apache configfile="/etc/httpd/conf/httpd.conf" statusurl="http://127.0.0.1/server-status" --group apache
Disabilita un nodo.
# pcs cluster stop nodeA.netlite.it
Comandi utili.
# pcs resource move apache nodeA.netlite.it # pcs resource stop apache nodeB.netlite.it # pcs resource disable apache nodeB.netlite.it # pcs resource enable apache nodeB.netlite.it # pcs resource restart apache
andrea
- Published in Non categorizzato, Sistemistica, Tips & Tricks, Virtualizzazione
Proxmox firewall sul Bridge esterno
A volte c’è la necessità di esporre direttamente su internet alcune VM utilizzando un bridge sull’interfaccia esterna.
Di default il bridge non fa transitare i pacchetti da netfilter quindi non è possibile implementare alcun controllo di sicurezza.
Per ovviare a questo comportamento basta attivare questa funzione con:
echo 1 > /proc/sys/net/bridge/bridge-nf-call-iptables
e per rendere definitive le modifiche, inserire in /etc/sysctl.conf:
net.bridge.bridge-nf-call-iptables = 1 net.bridge.bridge-nf-call-arptables = 1
a questo punto i pacchetti transiteranno dalle catene standard e sarà possibile attivare singolarmente le porte in ingresso ed in uscita utilizzando il modulo di controllo sull’interfaccia fisica:
iptables -A FORWARD -m physdev --physdev-out veth201.0 -m multiport -p tcp --dports 80 -j ACCEPT iptables -A FORWARD -m physdev --physdev-in veth201.0 -m multiport -p udp --dports 53 -j ACCEPT iptables -A FORWARD -m physdev --physdev-in veth201.0 -m multiport -p tcp --dports 80 -j ACCEPT
andrea
- Published in Sistemistica, Tips & Tricks, Virtualizzazione
PROXMOX tips venet e /usr/portage
Tips per la personalizzazione di contenitori (CT) PROXMOX
Mount automatico di /usr/portage
Utilizzando Gentoo come distribuzione Linux all’interno dei contenitori OpenVZ può essere utile condividere tra i contenitori la /usr/portage/ in modo da poter sincronizzarla tramite la macchina host e ridurre drasticamente l’occupazione di spazio disco.
Per ottenere questo è possibile far svolgere queste operazioni ad ogni boot della VM creando o modificando tramite shell ed editor di testo lo script {VMID}.mount nella stessa directory dove è presente il file {VMID}.conf.
Spostiamoci quindi nella directory:
cd /etc/pve/nodes/$(hostname -s)/openvz/
E creiamo (o modifichiamo) il file:
vim {VMID}.mount
Inserendo queste righe di codice:
#!/bin/bash
. /etc/vz/vz.conf
. ${VE_CONFFILE}
SRC=/var/lib/vz/portage
DST=/usr/portage
if [ ! -e ${VE_ROOT}${DST} ]; then
mkdir -p ${VE_ROOT}${DST};
fi
mount -n -t simfs ${SRC} ${VE_ROOT}${DST} -o ${SRC}
Lo script è molto comprensibile e non contiene alcun riferimento alla singola macchina virtuale per cui è possibile copiarlo per ogni macchina Gentoo ospitata.
Al termine è necessario cambiare i diritti di esecuzione:
chmod 700 {VMID}.mount
Nel caso, ad esempio, di volere mantenere lo storage ed il sistema su supporto diversi per questioni di spazio o performance può essere utile aggiungere allo script il mount anche di questi mountpoint:
#!/bin/bash
. /etc/vz/vz.conf
. ${VE_CONFFILE}
SRC=/var/lib/vz/portage
DST=/usr/portage
if [ ! -e ${VE_ROOT}${DST} ]; then
mkdir -p ${VE_ROOT}${DST};
fi
mount -n -t simfs ${SRC} ${VE_ROOT}${DST} -o ${SRC}
SRC=/storage/${VEID}/home
DST=/home
if [ ! -e ${VE_ROOT}${DST} ]; then
mkdir -p ${VE_ROOT}${DST};
fi
mount -n -t simfs ${SRC} ${VE_ROOT}${DST} -o ${SRC}
Qusto permette di avere la home di ogni contenitore su di uno storage separato.
Utilizzo questo sistema, ad esempio, per avere lo storage su di un filesystem ZFS con compressione realtime attiva.
Utilizzo delle interfaccie veth al posto di venet
Può essere necessario utilizzare caratteristiche di rete che le interfaccie venet non forniscono (ad esempio ARP) QUI.
Seguendo quindi la guida QUI, dopo aver configurato tramite l’interfaccia web di PROXMOX la nuova scheda di rete questa risulta correttamente aggiunta al bridge di rete ma la VM può risultare isolata.
#!/bin/bash
. /etc/vz/vz.conf
. ${VE_CONFFILE}
SRC=/var/lib/vz/portage
DST=/usr/portage
if [ ! -e ${VE_ROOT}${DST} ]; then
mkdir -p ${VE_ROOT}${DST};
fi
mount -n -t simfs ${SRC} ${VE_ROOT}${DST} -o ${SRC}
SRC=/storage/${VEID}/home
DST=/home
if [ ! -e ${VE_ROOT}${DST} ]; then
mkdir -p ${VE_ROOT}${DST};
fi
mount -n -t simfs ${SRC} ${VE_ROOT}${DST} -o ${SRC}
IP="XX.XX.XX.XX"
/sbin/ip route del $IP dev vmbr0 2>/dev/null
/sbin/ip route add $IP dev vmbr0 2>/dev/null
Alla fine dello script si nota la rimozione e l’aggiunta di una rotta verso il bridge che ospita la VM con l’indirizzo XX.XX.XX.XX.
Lo script purtroppo contiene una configurazione specifica per cui è necessario modificarlo per utilizzarlo per altre VM.
Esecuzione comandi all’interno di un Contenitore (CT) OpenVZ
Per eseguire comandi in un contenitore OpenVZ è possibile utilizzare il comando:
# vzctl exec 103 /etc/init.d/sshd status openssh-daemon is stopped # vzctl exec 103 /etc/init.d/sshd start Starting sshd: [ OK ]
Andrea Gagliardi – netlite.it
- Published in Sistemistica, Tips & Tricks, Virtualizzazione
Clonare Windows Server 2003 usando clonezilla per migrazione su Debian PROXMOX
Emerge spesso la necessità di clonare una macchina Windows esistente su hardware fisico, per utilizzarla poi come macchina virtuale su Debian PROXMOX.
Qui di seguito indicherò la procedura da noi adottata per clonare un Windows 2003 Server on the fly utilizzando CLONEZILLA.
On the fly intendo senza alcuna necessità di creare immagini su dischi esterni, ma direttamente sul disco remoto virtuale precedentemente configurato su PROXMOX.
Operazioni Preliminari:
- Installare sulla macchina windows esistente mergeide.reg , permette di abilitare i driver standard IDE su macchine del tipo winxp/win2003, il file è scaricabile dal seguente link mergeide.
- Scaricare la iso di CloneZilla e realizzare un cdrom/DVD.
- Preparare utilizzando l’interfaccia PROXMOX una macchina VM definita TARGET definendo un disco di dimensione >= al disco origine presente sul server Windows 2003 (con almeno 1Gb in eccesso rispetto all’originale).
- Assicurarsi di aver caricato sullo Storage PROXMOX la iso virtio-win.iso per l’installazione dei driver necessari alla macchina Windows una volta clonata (rete, disco) e la iso precedentemente scaricata di CloneZilla.
A questo punto è possibile procedere come descritto di seguito.
Inserire il cd di clonezilla nel lettore della macchina fisica da clonare che chiameremo SOURCE. Riavviare la macchina e se server configurare il bios per fare il boot da lettore cdrom.
Da interfaccia CloneZilla presente sulla macchina SOURCE selezionare l’opzione “disk_to_remote_disk” (copia disco da rete).
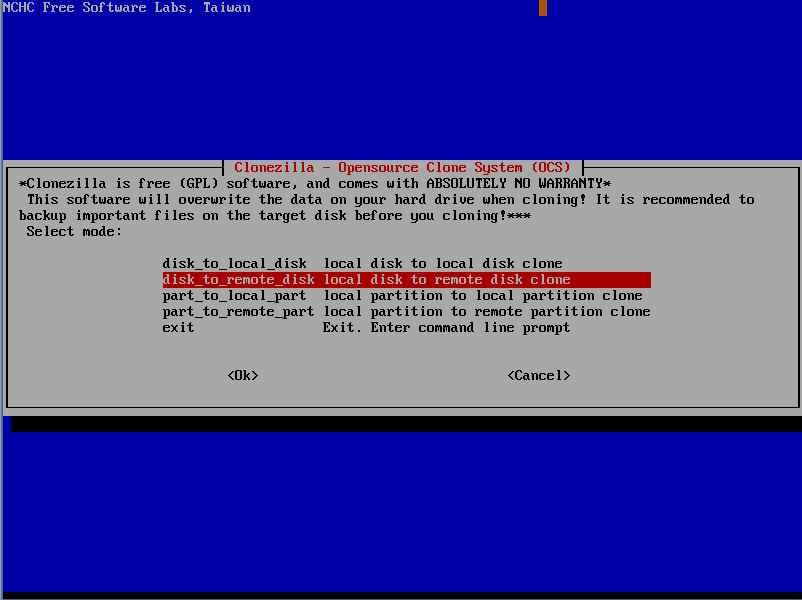
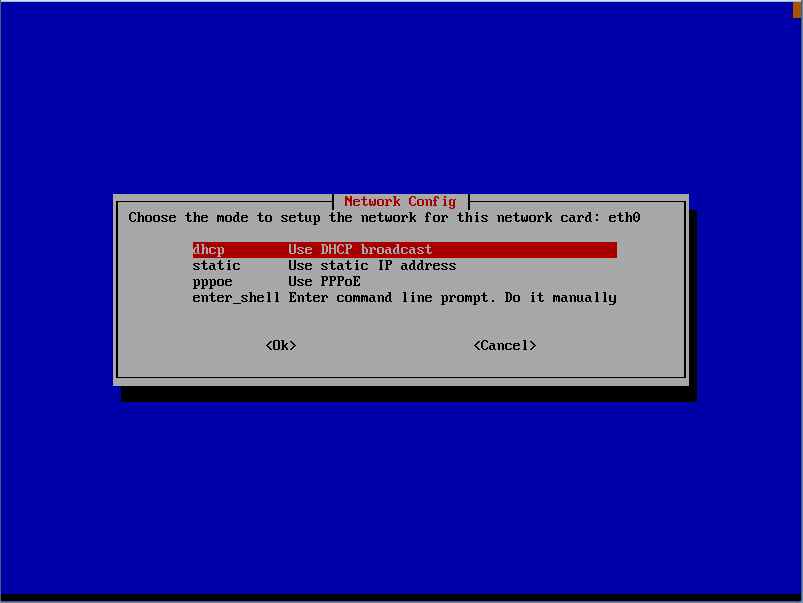
Procedere oltre e scegliere
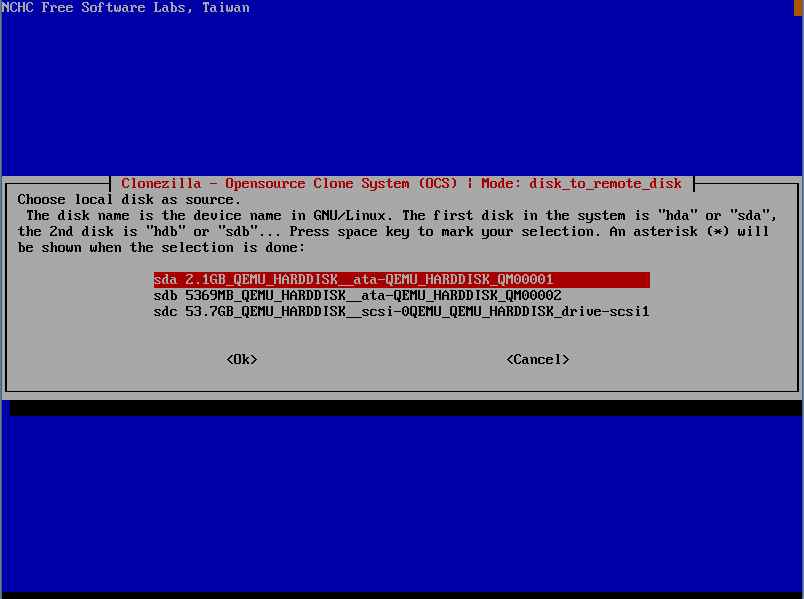
se presente di configurare la rete tramite dhcp o manualmente (static). Nel nostro caso essendo Windows 2003 un dhcp server abbiamo scelto static inserendo l’ip a mano.
Passo successivo selezionare il disco da copiare come SOURCE.
A questo punto dopo alcuni altri passi di semplice comprensione la macchina source sarà pronta
per il trasferimento del disco via rete alla macchina TARGET.
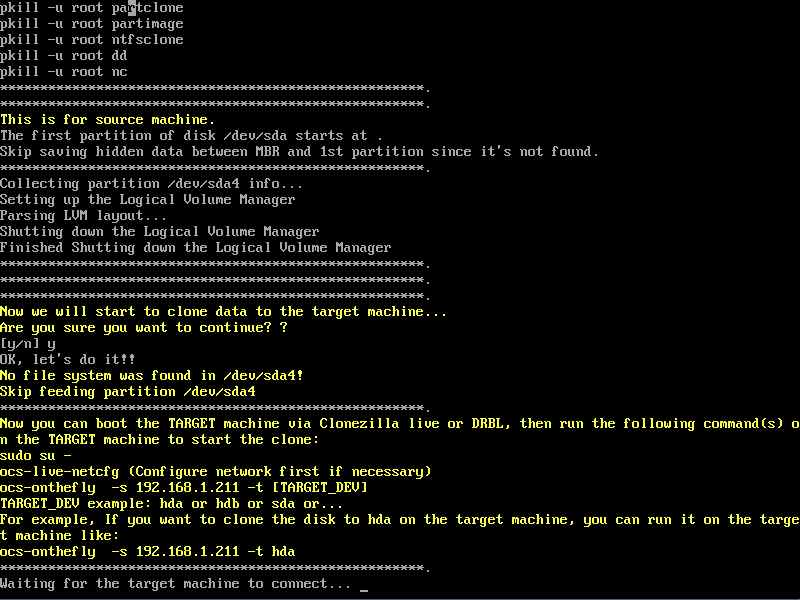
Macchina TARGET (precedentemente configurata tramite interfaccia PROXMOX)
Selezionare tramite interfaccia PROXMOX il boot della macchina TARGET da iso di clonezilla. Premere start e iniziare la configurazione da interfaccia Clonezilla
Entrare in modalità shell di ConeZilla.
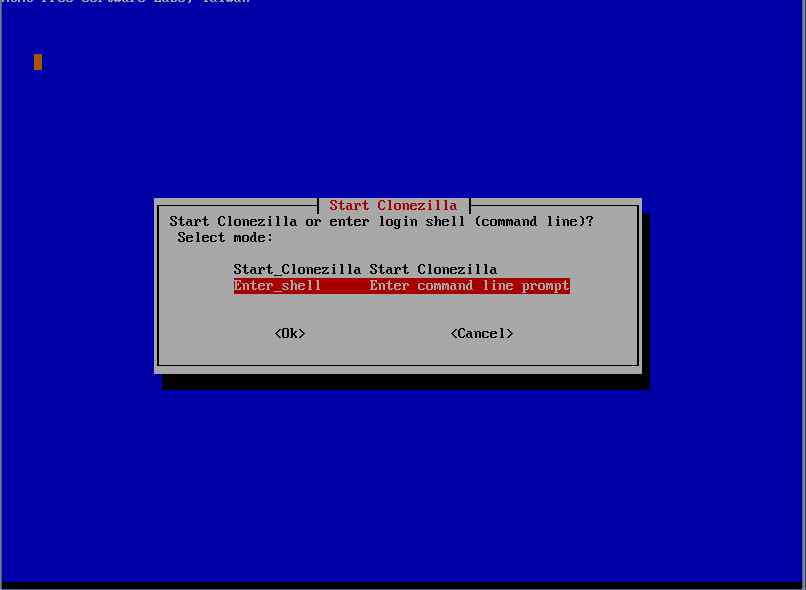
Eseguire i seguenti comandi nell’ordine indicato :
- sudo su
- fdisk /dev/sda (assicurarsi che il disco della macchina TARGET sia sda o simile) , uscire da fdisk digitando il comando ‘w’.
Sempre da shell di CloneZilla Eseguire
- ocs-live-netcfg
- ocs-onthefly -s IPSOURCE -t sda (IPSOURCE = indirizzo ip macchina source)
A questo punto inizierà la copia del disco.
Apparirà una finestra che indica il tempo stimato e le partizioni da copiare (copiare anche la partizione di boot di windows).
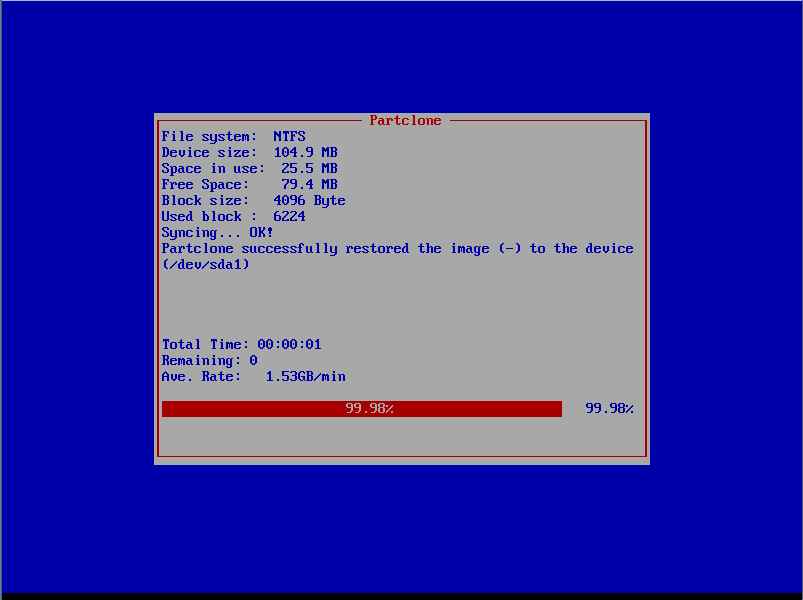
Una volta finito il processo, basterà toglire da proxmox il boot da iso di clonezilla ed avviare la macchina clonata con Start.
Una volta avviata sarà, come indicato nei preliminari, necessario installare i driver di rete virt0 o intel e1000 (consigliata in questo ultimo caso l’installazione direttamente
usando i driver scaricati dal sito Intel).
Sarà necessario riattivare la licenza di Windows 2003 server e inserire o verificare i parametri di rete della macchina TARGET.
La macchina source potrà essere spenta dopo aver verificato il corretto funzionamento della macchina TARGET.
- Published in Sistemistica, Tips & Tricks, Virtualizzazione
PROXMOX calcolo cpu units
Con Proxmox è possibile assegnare tempo macchina garantito alle VM tramite l’assegnazione di CPU UNITS.
Tramite il comando
# vzcpucheck Current CPU utilization: 4000 Power of the node: 3191600
E’ possibile stabilire la potenza del nodo.
Quindi per assegnare l’1% della potenza ad una VM occorre fare questo calcolo:
3191600 / 100 * 1 = 31916
Allo stesso modo per assegnare il 5% della potenza ad una VM occorre fare questo calcolo:
3191600 / 100 * 5 = 159580
Da quello che abbiamo potuto verificare per i contenitori openvz la modifica è istantanea per le vm KVM occorre spegnerle e riaccenderle.
andrea gagliardi – netlite.it
- Published in Sistemistica, Tips & Tricks, Virtualizzazione
PERC H300 megaraid_sas su Debian PROXMOX
Installando un sistema Linux Server, tipo Proxmox (Debian), è possibile monitorare lo stato di funzionamento del controller RAID PERC H700 alias LSI MegaRAID.
Seguendo le indicazioni sul sito hwraid.le-vert.net
E’ possibile aggiungere in /etc/apt/sources.list il repository
deb http://hwraid.le-vert.net/debian wheezy main
ed aggiungere la chiave:
wget -O - http://hwraid.le-vert.net/debian/hwraid.le-vert.net.gpg.key | apt-key add
ad un successivo apt-get update verranno resi disponibili alcuni tools
apt-get install megaclisas-status megacli
è possibile invocare direttamente megaclisas-status
# megaclisas-status -- Controller informations -- -- ID | Model c0 | PERC H700 Integrated -- Arrays informations -- -- ID | Type | Size | Status | InProgress c0u0 | RAID10 | 2454G | Optimal | None -- Disks informations -- ID | Model | Status c0u0p0 | SEAGATE ST900MM0006 LS08S0N08XHB | Online, Spun Up c0u0p1 | SEAGATE ST900MM0006 LS08S0N08896 | Online, Spun Up c0u0p0 | SEAGATE ST900MM0006 LS08S0N08X1K | Online, Spun Up c0u0p1 | SEAGATE ST900MM0006 LS08S0N08875 | Online, Spun Up c0u0p0 | SEAGATE ST900MM0006 LS08S0N07EBR | Online, Spun Up c0u0p1 | SEAGATE ST900MM0006 LS08S0N084P0 | Online, Spun Up
oppure fare affidamento sul demone già attivo dopo l’installazione e far rilevare la presenza in /var/run del file megaclisas-statusd.status
Andrea – netlite.it
- Published in Sistemistica, Tips & Tricks, Virtualizzazione
Cluster Fencing Two Node DRBD PROXMOX
Documentazione completa LINK
Per l’installazione e l’utilizzo del DRBD è preferibile che vi sia almeno una scheda di rete dedicata alla sincronizzazione configurata in /etc/network/interfaces su ogni nodo.
# network interface settings
auto lo
iface lo inet loopback
iface eth0 inet manual
auto eth1
iface eth1 inet static
address 10.0.7.106
netmask 255.255.240.0
auto vmbr0
iface vmbr0 inet static
address 192.168.7.106
netmask 255.255.240.0
gateway 192.168.2.1
bridge_ports eth0
bridge_stp off
bridge_fd 0
Tuning dello strato di rete per DRBD da inserire in rc.local
echo 30000 > /proc/sys/net/ipv4/tcp_max_syn_backlog echo 50000 > /proc/sys/net/core/netdev_max_backlog
Nel caso di DRBD su 2 x 10Gb SFP+ in bonding la configurazione ha dato i risultati sperati e le prestazioni sono state di circa 400Mbytes/sec in TCP e 800Mbytes/sec in UDP, l’innalzamento dell’MTU e del TXQUEUELEN hanno migliorato sensibilmente le performances
ifconfig eth3 mtu 9000 ifconfig eth4 mtu 9000 ifconfig bond0 mtu 9000 ifconfig eth3 txqueuelen 5000 ifconfig eth4 txqueuelen 5000 ifconfig bond0 txqueuelen 5000
Si passa all’installazione dei tools necessari
apt-get install drbd8-utils
Sulla porzione di disco (o sul pool di dischi) da destinare al DRBD (ipotizziamo sdb) si crea una partizione di tipo 8e (Linux LVM)
Si modificano i files di configurazione /etc/drbd.d/global_common.conf
global { usage-count no; }
common { syncer { rate 30M; verify-alg md5; } }
e /etc/drbd.d/r0.res
resource r0 {
protocol C;
startup {
wfc-timeout 0; # non-zero wfc-timeout can be dangerous (http://forum.proxmox.com/threads/3465-Is-it-safe-to-use-wfc-timeout-in-DRBD-configuration)
degr-wfc-timeout 60;
become-primary-on both;
}
net {
cram-hmac-alg sha1;
shared-secret "my-secret";
allow-two-primaries;
after-sb-0pri discard-zero-changes;
after-sb-1pri discard-secondary;
after-sb-2pri disconnect;
#data-integrity-alg crc32c; # has to be enabled only for test and disabled for production use (check man drbd.conf, section "NOTES ON DATA INTEGRITY")
}
on proxmox-105 {
device /dev/drbd0;
disk /dev/sdb1;
address 10.0.7.105:7788;
meta-disk internal;
}
on proxmox-106 {
device /dev/drbd0;
disk /dev/sdb1;
address 10.0.7.106:7788;
meta-disk internal;
}
}
Si fa partire il servizio drbd con
/etc/init.d/drbd start
e si creano i metadata
drbdadm create-md r0
dopodichè si attivano i device su entrambi i nodi
drbdadm up r0
E’ possibile visualizzare lo stato del drbd con
pve1:~# cat /proc/drbd
version: 8.3.13 (api:88/proto:86-90)
GIT-hash: dd7985327f146f33b86d4bff5ca8c94234ce840e build by root@oahu, 2009-09-10 15:18:39
0: cs:Connected ro:Secondary/Secondary ds:Inconsistent/Inconsistent C r----
ns:0 nr:0 dw:0 dr:0 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:b oos:2096348
Su di un solo nodo digitare
drbdadm -- --overwrite-data-of-peer primary r0
per avviare la sincronizzazione e riabbiare il drbd su entrambi i nodi per attivare la risorsa in modalità attivo/attivo con
/etc/init.d/drbd stop /etc/init.d/drbd start
Tuning per performance DRBD 8.3 LINK
resource resource {
net {
max-buffers 8000;
max-epoch-size 8000;
...
}
...
}
resource resource {
net {
sndbuf-size 0;
...
}
...
}
resource resource {
syncer {
al-extents 3389;
...
}
...
}
resource resource {
disk {
no-disk-barrier;
no-disk-flushes;
...
}
...
}
A questo punto è possibile configurare LVM editando /etc/lvm/lvm.conf
# By default we accept every block device: filter = [ "r|/dev/sdb1|", "r|/dev/disk/|", "r|/dev/block/|", "a/.*/" ]
per eliminare sdb1 dall’autoscan
e si crea un device con
pvcreate /dev/drbd0 vgcreate [VG_NAME] /dev/drbd0
Tramite l’interfaccia web è possibile aggiungere il disco LVM/DRBD
Documentazione completa LINK
Dopo l’installazione e l’aggiornamento dei nodi su uno di essi si crea il cluster
pvecm create [CLUSTER_NAME]
Per aggiungere nodi al cluster sul nodo da aggiungere si digita
pve add [CLUSTER_IP_ADDRES]
Per verificare lo stato del cluster
pvecm status pvecm nodes
Per rimuovere un nodo
pvecm delnode [NODE_NAME]
Una volta instaurato il cluster con due nodi non è possibile spegnere un nodo senza perdere la possibilità di editare i files di configurazione o di effettuare backup o creare vm in quanto non viene raggiunto il quorum necessario che si ottiene con configurazioni tipiche di 3 nodi.
E possibile abbassare temporaneamente o definitivamente il quorum a 2 o aggiungere un quorumdisk.
Documentazione completa LINK
Per configurare il fencing occorre modificare il file /etc/pve/cluster.conf
cp /etc/pve/cluster.conf /etc/pve/cluster.conf.new
Ed aumentare di +1 il valore di config_version=”XX”
Nella sezione cman aggiungere expected_votes=”1″
Situazione che è possibile forzare anche manualmente con il comando
pvecm expected 1
E dopo
E’ preferibile usare ipaddr=”192.168.1.2″ al posto di hostname=”nodeA”
Poi modificare clusternode
Per applicare le modifiche nell’interfaccia web di gestione datacenter nel tab HA è possibile Attivare le modifiche, queste verranno applicate all’intero cluster.
Eventuali errori di configurazione vengono segnalati in fase di applicazione.
Documentazione completa LINK
Per attivare il fencing bisogna aggiungere ogni nodo al dencing domain
Si modifica /etc/default/redhat-cluster-pve affinchè contenga
FENCE_JOIN="yes"
E si lancia il comando su ogni nodo
fence_tool join
Per verificare lo stato
fence_tool ls
Per installare un quorum disk iSCSI presente su di un NAS
apt-get install tgt vi /etc/iscsi/iscsid.conf # change node.startup to automatic /etc/init.d/open-iscsi restart
Selezionare il target
iscsiadm --mode discovery --type sendtargets --portal [iSCSI_IP] iscsiadm -m node -T iqn.[BLAHBLAH] -p [iSCSI_IP] -l
Create una partizione primaria con fdisk e create il quorumdisk
mkqdisk -c /dev/sdc1 -l proxmox1_qdisk
Per inserirlo nella configurazione si procede come sopra
cp /etc/pve/cluster.conf /etc/pve/cluster.conf.new
si incrementa di +1 la config_version si rimuove two_node=”1″ e si aggiunge la definizione quorumd
Sempre dall’interfaccia web nel tab HA si applica la modifica, si verifica lo stato con
pvecm s
e si applicano le modifiche con
/etc/init.d/rgmanager stop # This will restart any VMs that are HA enabled onto the other node. /etc/init.d/cman reload # This will activate the qdisk
Assicurarsi che rgmanager sia partito o avviarlo e verificare che su ogni nodo clustat riporti qualcosa del tipo
Cluster Status for proxmox1 @ Thu Jun 28 12:23:10 2012 Member Status: Quorate Member Name ID Status ------ ---- ---- ------ proxmox1a 1 Online, Local, rgmanager proxmox1b 2 Online, rgmanager /dev/block/8:33 0 Online, Quorum Disk
Configurazione finale
- Published in Sistemistica, Tips & Tricks, Virtualizzazione
HP Smart Array P410i su Debian Proxmox
Installando un sistema Linux Server, tipo Proxmox (Debian), è possibile monitorare lo stato di funzionamento del controller RAID hardware HP Smart Array P410i.

In /etc/apt/sources.list.d è possibile creare un file hp.list contenente:
deb http://downloads.linux.hp.com/SDR/repo/mcp/ wheezy/current non-free
curl http://downloads.linux.hp.com/SDR/hpPublicKey1024.pub | apt-key add - curl http://downloads.linux.hp.com/SDR/hpPublicKey2048.pub | apt-key add - curl http://downloads.linux.hp.com/SDR/repo/mcp/GPG-KEY-mcp | apt-key add - [code] ad un successivo apt-get update verranno resi disponibili alcuni tools di HP tipo hpacucli [code] apt-get install hpacucli
è possibile invocare direttamente hpacucli
# hpacucli controller slot=0 ld all show Smart Array P410i in Slot 0 (Embedded) array A logicaldrive 1 (558.7 GB, RAID 1+0, OK) array B logicaldrive 2 (931.5 GB, RAID 1, OK) # hpacucli controller all show config detail Smart Array P420i in Slot 0 (Embedded) Bus Interface: PCI Slot: 0 Serial Number: 5001438023BB5E90 Cache Serial Number: PBKUA0BRH3U0X9 RAID 6 (ADG) Status: Disabled Controller Status: OK Hardware Revision: B Firmware Version: 3.42 Rebuild Priority: Medium Expand Priority: Medium Surface Scan Delay: 3 secs Surface Scan Mode: Idle Queue Depth: Automatic Monitor and Performance Delay: 60 min Elevator Sort: Enabled Degraded Performance Optimization: Disabled Inconsistency Repair Policy: Disabled Wait for Cache Room: Disabled Surface Analysis Inconsistency Notification: Disabled Post Prompt Timeout: 15 secs Cache Board Present: True Cache Status: OK Cache Ratio: 25% Read / 75% Write Drive Write Cache: Enabled Total Cache Size: 512 MB Total Cache Memory Available: 304 MB No-Battery Write Cache: Enabled Cache Backup Power Source: Capacitors Battery/Capacitor Count: 1 Battery/Capacitor Status: OK SATA NCQ Supported: True Spare Activation Mode: Activate on drive failure Controller Temperature (C): 64 Cache Module Temperature (C): 32 Capacitor Temperature (C): 28 ............. .............
per attivare la write cache:
# hpacucli controller slot=0 modify dwc=enable
oppure utilizzare il plugin nagios
# wget 'http://exchange.nagios.org/components/com_mtree/attachment.php?link_id=674&cf_id=24' -O check_hparray # ./check_hparray -s 0 RAID OK - (Smart Array P410i in Slot 0 (Embedded) array A logicaldrive 1 (558.7 GB, RAID 1+0, OK) array B logicaldrive 2 (931.5 GB, RAID 1, OK))
Maggiori info qui QUI
Andrea - netlite.it
- Published in Sistemistica, Tips & Tricks, Virtualizzazione
Bond tra interfacce di rete in Proxmox
Avendo più interfacce di rete disponibili ed utilizzando switch dotati di link aggregation è possibile unire le interfacce in un bond sul quale appoggiare il bridge.
Questo deve essere configurato manualmente in quanto l’interfaccia web di proxmox non prevede questo utilizzo.
/etc/network/interfaces
auto lo
iface lo inet loopback
auto eth0
iface eth0 inet manual
bond-master bond0
mtu 9000
auto eth1
iface eth1 inet manual
bond-master bond0
mtu 9000
auto bond0
iface bond0 inet manual
mtu 9000
bond-mode 802.3ad
bond-miimon 100
bond-slaves none
bond-lacp-rate 4
auto vmbr0
iface vmbr0 inet static
mtu 9000
address 192.168.1.1
netmask 255.255.255.0
network 192.168.1.0
bridge_ports bond0
bridge_stp off
bridge_fd 0
post-up route add -net 10.1.1.0 netmask 255.255.255.0 gw 192.168.2.254
pre-down route del -net 10.1.1.0 netmask 255.255.255.0 gw 192.168.2.254
Il traffico di rete si distribuirà in modo automatico (e non bilanciato) sulle due interfacce aumentando sensibilmente la banda di rete utilizzata.
# ifconfig eth0
eth0 Link encap:Ethernet HWaddr 00:26:55:ec:ef:b6
UP BROADCAST RUNNING SLAVE MULTICAST MTU:1500 Metric:1
RX packets:82172110 errors:0 dropped:0 overruns:0 frame:0
TX packets:366333813 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:32549246640 (30.3 GiB) TX bytes:1142227109649 (1.0 TiB)
Interrupt:24 Memory:feb80000-feba0000
# ifconfig eth1
eth1 Link encap:Ethernet HWaddr 00:26:55:ec:ef:b6
UP BROADCAST RUNNING SLAVE MULTICAST MTU:1500 Metric:1
RX packets:543001774 errors:0 dropped:0 overruns:0 frame:0
TX packets:366337469 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:237725677253 (221.3 GiB) TX bytes:469115298143 (436.8 GiB)
Andrea – Netlite.it
- Published in Sistemistica, Tips & Tricks, Virtualizzazione
- 1
- 2